The Oil Shock Model was first developed by
Webhubbletelescope and is explained in detail in The Oil
Conundrum. (Note that this free book takes a while to download as it is
over 700 pages long.) The Oil Shock Model with Dispersive Discovery is covered
in the first half of the book. I have
made a few simplifications to the original model in an attempt to make it
easier to understand.

Figure 1
In a previous
post I explained convolution and its use in modelling oil output in the
Bakken/Three Forks and Eagle Ford LTO (light tight oil) fields. Briefly, an average hyperbolic well profile
(monthly oil output) is combined with the number of new wells completed each
month by means of convolution to find a model of LTO output.
In the Oil Shock model the maximum entropy probability
distribution is analogous to the average well profile and the annual oil
discoveries are analogous to the number of new well completions in my LTO
models.
The maximum entropy probability distribution is used when we
know there is a probability distribution but we have very little information about
what it looks like. In this case, the
only assumption that is made is that a probability distribution exists and that
it has a positive mean and a standard deviation. The maximum entropy probability distribution
sets the mean equal to the standard deviation and has the form
m=k*exp(-k*t)
wherem=probability that a discovery will become a producing reserve t years after discovery,
k=a constant set at 0.05 in my models, where 1/k is the mean number of years from discovery to producing reserve (20 years), and
t=years from discovery to producing reserve.
This is also called the negative exponential distribution
see http://en.wikipedia.org/wiki/Exponential_distribution
The maximum entropy principle was first proposed by E.T.
Jaynes see
http://en.wikipedia.org/wiki/Edwin_Thompson_Jaynes.
If 1000 kb was discovered when t=0 and if m=0.049(or 4.9%) when
t=1, then 1000*0.049=49 kb of new producing reserves are added to cumulative
producing reserves in year 1. (Where year 1 means one year from the date of discovery.)
Chart below shows the Maximum Entropy Probability (MaxEnt),
m vs year from first discovery.

Figure 2

Figure 3
The figure above is from Jean Laherrere’s final post at the
Oil Drum (figure 7). The figure below is figure 9 from the same Oil Drum post.

Figure 4
These two charts were used to estimate backdated discoveries
of proved plus possible (2P) C+C excluding extra heavy(XH) oil reserves from
1901 to 2010, I read the data from the charts as best I could. (The green curves in both figure 3 and figure 4.) In my opinion Jean Laherrere provides the best oil discovery estimate
that is publicly available.
In an attempt to match Jean Laherrere’s model, I used
Webhubbletelescope’s dispersive discovery model and fit this model to the
discovery data.
The dispersive discovery model describes cumulative discovery,
D in the following equation
D=U/(1+C/t^6) where
U=URR=2,200,000 million barrels (for the model presented here),
C=constant determined by best fit to discovery data, in this
case C=800 trillion, and
t= year where t=0 is 1870, t=1 is 1871, etc.
The rationale behind this equation is developed in The Oil
Conundrum in Chapter 9, pp 167-177,
particularly pp. 170-171 equations 9-25 and 9-28. The combination of those two equations is the
basis for the cumulative discovery(D) relationship above.
The chart below shows the model fit to Jean Laherrere’s
discovery data. The vertical axis is
millions of cumulative barrels discovered.

Figure 5
The following chart shows yearly discoveries(real), the
centered 25 year average for discoveries and the dispersive discovery model.
Vertical axis is millions of barrels per year.

Figure 6
The discovery model can be convolved with the maximum
entropy probability distribution to find the new producing reserves (n) that
are added to the cumulative producing reserves (P) each year using a simple
spreadsheet to add it all up. In the chart below the vertical axis is millions of barrels per year of new producing reserves (reserves which begin producing in a given year.)

Figure 7
The next step is to find the cumulative producing reserves,
P. Each year oil is extracted from P and
reserves are added (n).
P2=P1+n-e where
P2 are the cumulative producing reserves at the end of year
2
P1 are the cumulative producing reserves at the end of year
1
n= new producing reserves added to P1 in year 2
e= oil extracted (or produced) from P1 in year 2
r=e/P1= extraction rate
Actual production data for C+C-XH is used to determine the
extraction rate necessary for the model to match the output data. The chart below shows the cumulative producing reserves
and extraction rate for C+C less extra heavy oil which matches the output data
from 1960 to 2014.
The model from 2015 to 2050 is based on the underlying model for
new producing reserves added each year and the assumed extraction rates. These
rise a little from 2015 to 2021 from 5.5% to 5.8% and then remain flat. Over
the 2009 to 2015 period extraction rates rose from 4.7% to 5.5%.

Figure 8
Below is Jean Laherrere’s estimate of 2P technical reserves
for C+C-XH, from the Oil Drum Post referenced above.

Figure 9
In 2010 the model producing reserves are about 62% of the 2P
technical reserves estimated by Jean Laherrere(850 Gb in 2010).
For more mature regions, such as the US and Norway,
producing reserves are about 78% to 80% of 2P reserves when we assume 2P
reserves are about 33% higher than 1P reserves for the US (Norway reports 2P
reserves, but the US EIA reports 1P reserves).
This model uses a separate model for extra heavy oil because
the time it takes to develop extra heavy oil resources is different from
C+C-XH. There are 500 Gb of extra heavy oil URR and 2200 Gb of C+C-XH URR for a World total C+C URR of 2700 Gb.
Figure 1
The following chart shows the discovery model, new producing reserves, and C+C-XH output in Gb per year.
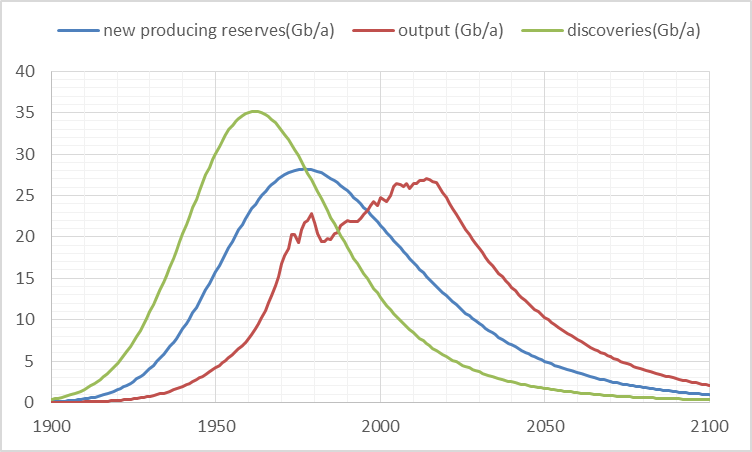
Figure 10
In the original Oil shock model there were several stages
between discovery and production called fallow, build, and mature. Each stage involved convolution similar to
the convolution I used here with the maximum entropy probability distribution
and the discovery data, but in the original model there were three such maxent
probability distributions and three convolutions rather than just one.
It seemed too complicated to explain all that so I collapsed
the fallow, build, and maturation stages of the original model into a single
convolution where we go directly from the discovery stage to the new producing
reserve stage (which is essentially the same as the mature reserves of the
original model.)
In a future post I will show how potential reserve growth
could lead to a higher URR of C+C less extra heavy oil than suggested by Jean
Laherrere. This implies that the model presented here may be a little on the
pessimistic side.
This comment has been removed by the author.
ReplyDeleteGood work. Coincidentally, I published an update to the Loglet Analysis almost on the same day:
ReplyDeletehttp://attheedgeoftime.blogspot.com/2015/02/loglets-revisited.html
It is interesting to see how results improve by unbundling NGLs from crude. The next step is to unbundle heavy petroleums and model those separately; this requires a good time series on extraction, whereas with the Shock Model the implied discovery is sufficient.
Jean has been using a ballpark figure of 500 Gb for the heavy petroleums ultimate. Check for instance this article:
http://aspofrance.viabloga.com/files/JL_Clarmix-Previsions1900-2100.pdf
You might profit from discussing this issue directly with him.
Regards.
Thank you Luis.
DeleteI very much enjoyed your work at the Oil Drum, and I will check out your blog.
I have read a lot of Jean Laherrere's work, but only the stuff in English, my French is horrible.
The model presented here uses Laherrere's 2200 Gb for C+C less extra heavy and his 500 Gb estimate for extra heavy oil. I did a separate shock model (not presented here) to model extra heavy oil output. I used his Oil Drum articles and the following paper (in English)
http://aspofrance.viabloga.com/files/JL_2013_oilgasprodforecasts.pdf
Dennis: You're not going to like this comment and I really don't want to debate you. Please at least listen and let it rattle around as an observation:
ReplyDeleteI'm pretty leery of this stuff. It's a lot worse than the simple Bakken peak models you are doing based on USGS resource estimate and well assumptions. Those won't be perfect...but they are at least a clear logic and allow doing scenarios and thinking about how the production responds over time to different inputs.
This "oil shock" and thermodynamics and poisson distribution lacks a good physical rationale. In fact, it shows poor physics by taking something that happens to give bell-ish shaped curves and then gives the false idea that there is something similar in a TIME SERIES FOR A HUMAN ACTIVITY as compared to distributions of gas molecules or observations of variables or the like. Time series are a very different thing than distributions of variables. I think you would be a lot better off just saying "I feel like fitting some exponentials and making a bell curve" than with false physical intuitions.
In addition the stuff is not peer reviewed and not clearly explained. And I'm sorry, but 700 page self published Internet stuff? Yikes.
Hi Nony,
DeleteIt is clear to me. The maximum entropy distribution is very well established in peer reviewed literature, just google E. T. Jayne. The concept has wide applications. In very simple terms, we do not know the time it takes to develop the average oil discovery from the time of discovery to the time the oil becomes a producing reserve. This varies from discovery to discovery and for the barrels within any given discovery. The maximum entropy distribution is used when we have a minimum of information about the actual probability distribution, the only assumption is that there is a probability distribution that has a mean and standard deviation which are the same (this requires the minimum amount of information and results in maximum entropy). The cumulative discovery model is based on a random search of the earth's crust for oil and fits actual discovery data very well. The combination of a guess of 20 years for the average time from discovery to producing reserve as a negative exponential distribution, with oil discovery data and oil production data, produces a model which matches the data very well.
As I said in the post the model presented uses Jean Laherrere's somewhat pessimistic estimate for a C+C URR of 2700 Gb, my estimate would be about 3100 Gb and the USGS estimate would be 3500 Gb if extra heavy oil URR is 500 Gb, and 4000 Gb if extra heavy oil is 1000 Gb.
The extra heavy oil will take a very long time to develop and the differences from now to 2100 for estimates of 500 Gb of extra heavy oil and 1000 Gb of extra heavy oil URR will be negligible.
ET Jaynes did not write about petroleum production time series. He described the basic statistical method and not in the context of time series, but of sampling. The arguments for some sort of peak oil insights come from the self-published Internet, not specialist academic literature.
ReplyDeleteI remain thinking this is "science-y" [similar to "truth-y" of Colbert] rather than scientific. I question the value of all this math and statistics and fancy names for the subject at hand (a time series of human activity with at least some drivers based on price, demand, technology, political access...factors that are more than monkeys drilling the globe randomly sampling it.). Even in the random monkey drilling sampling case, I hesitate to say that the maxent distribution should be the default assumption (versus just a normal distribution). Like is it "better" (as a predictor, for curve fitting) in any way since you've used this pet distribution with the fancy shmancy name (and one held in relative disrepute in standard statistical thermodynamics...read the criticisms section of the Wiki article).
You also don't deal with the issue of backdating of discovery volumes. http://www.forbes.com/sites/michaellynch/2014/07/07/peak-oil-4-the-urban-legend-of-inadequate-discoveries/
I guess we could "debate" it. But I'm unlikely to read the 700 page background. Even if you disagree with me...I would take it as a serious observation from a guy who's done plenty of hard science and plenty of engineering and economic analysis, that this stuff about oil shocks and maximum entropy smells like basic curve fitting dressed up with fancy words and models, but not with more predictive value because of it.
normal probably not good. But maybe log normal
ReplyDeleteHi Nony,
ReplyDeleteThe maximum entropy probability distribution makes the minimum assumptions, that is all. We are modelling something that we have very little knowledge about, the time between an oil discovery and the start of production of those resources. If we are going to assume a log-normal distribution we need some information about the mean and standard deviation of the distribution, in this case we do not have sufficient data to make any such determination and statistically the maximum entropy distribution makes the minimum assumptions, we assume the mean is positive (oil is discovered before we produce it) and that it is equal to the standard deviation. If you are a serious scientist, this would not need to be explained. The backdated discoveries are the only data I have to work with, reserve growth is easily built into the model, that is how I create models with higher URR than this first model I presented. Nobody can predict the future. We work with the data we have and extraction rates are indeed fit to the make the model match the data, the discovery model is also fit to the discovery data we have, the URR is based in part on Hubbert Linearization, and the expert judgement of the USGS and of Jean Laherrere.
Hi Nony,
DeleteBackdating reserve growth to the date of discovery really changes nothing. I am not making the argument that Lynch is talking about, so the article does not really apply at all.
I think the key assumptions are reserves. The maximum entropy is a bunch of distraction.
ReplyDeleteIf the "discoveries" actually include backdated amounts of oil, then your whole picture of discovery leading to production is changed. I would be very interested to see an actual source FROM THE YEAR that shows the amount of discovered oil as it is in your graph.
I think the key issue that your model shows a peak happening almost immediately and relatively steep (and that you intuitively don't trust that) shows that you are suspicious of some of the limitations of your method even if you can't articulate them.
Hi Nony,
DeleteIn this initial presentation I purposely used a URR that I thought was too low. I do not have acces to the source of Jean Laherrere's data, it is proprietary and I don't have the $$ to afford it. The data is backdated discoveries as of 2010. A better estimate of the URR for C+C less extra heavy oil is between 2500 Gb (based on Hubbert Linearization) and 3100 Gb (USGS mean estimate), I just take the average at 2800 Gb and add 500 Gb of extra heavy oil for a 3300 Gb C+C URR.
So bottom line, the method is sound in my opinion and uses a bottom up method which is superior to a simple Hubbert curve which has no foundation (unless a number of assumptions are added to the Shock model and the Hubbert curve can be derived.) The shock model is more general and is by no means perfect, but it uses discovery data plus reserve growth and Hubbert Linearization to find a reasonable URR and then production data to estimate extraction rates from 1960 to 2014. These extraction rates are used as a basis for a guess about future extraction rates. An improved model might try to tie extraction rates to GDP or oil prices or both, but we would then need to guess future oil prices and GDP. We could use EIA or the futures curve for oil prices and IMF for estimates of GDP growth as a substitute for a pure guess. Nobody knows the future, however, so every scenario or forecast is likely to be wrong. Sure you are not interested in POB, it seems bad behavior is more acceptable these days (and I didn't think you were that bad at POB, but I am not as pessimistic as some so that may influence my view of your comments.) I think your polite here, you don't berate someone, you just disagree.
Dennis, "Mike" here from POB, rather, AOBB (Anti-Oil Barrel Blog). Count the oilmen left on that blog at the end of the day and tell me its not a pity, all that. It was hijacked, plain and simple.
ReplyDeleteStay the course on your argument against Etp models and BW Hill. The value of anything in life, even life itself, is totally subjective and rooted in human emotions. Things are difficult in the oilfield at the moment; I don't need another mouth to feed. Nevertheless, I bought another horse today because he was a happy horse and he drives like a BWM. He had a twinkle in his big eyes that made me happy. There was an emotional component to my decision that circumvented need. Emotions separate human beings from trees. Fear, for instance of not being about move about, to stay warm, is the most powerful of human emotions.
The idea that oil will be worthless someday (very soon, apparently) based on energy vested for that returned, is absurd. His is a concept made to fit an idealistic view of a future he believes in. It is no coincidence that those who share his beliefs about the future, also embrace his model.
Don't give up on this; you are doing great! This hooey of his has always driven me nuts!!
Mike
Hey Mike,
DeleteI would encourage you to contact Ron, do you have his email, mine is dcoyne78 at gee male dot com, if you would like to chat. I miss your knowledge over at POB. Thanks for the encouragement, I think it it is not worth wasting my time banging my head against the wall on the etp thing.
This comment has been removed by the author.
ReplyDeleteThanks for sharing your idea.
ReplyDeletePackers and Movers Vijayawada
Packers and Movers Kolkata
Packers and Movers Ahmedabad
Packers and Movers Chandigarh
Thanks for sharing the article...
ReplyDeletePackers and Movers Bangalore
Packers and Movers Chennai
Packers and Movers Hyderabad
Packers and Movers Delhi
The exceptional element of the Quickbooks POS Error 3180 is the Ring deals which is a discretionary standardized identification scanner. It will customize all the client data for the CRM. At that point, there is track your stock where your stock will dependably be fully informed regarding each exchange occurring and in addition giving you the understanding of what is best for you.
ReplyDeleteQuickBooks Point of Sale is a far reaching arrangement from Intuit planned from little and medium retail ventures. It performs fundamental activities like deals, following stock and overseeing client connection proficiently. This application is accessible in Basic and Pro form.
ReplyDeleteQuickbooks POS Error 193.
If You can't handle satisfying time that you should location a cellphone at Norton Antivirus Phone Number then seek out for the tactic down beneath only. To stop obtaining the Norton server antivirus read through extra Help dial Norton antivirus customer support phone number you may have got to grasp the put together of motion that is absolutely well-informed about down in this article. It may properly present-day you Using the resolution which you will be making an attempt by contacting norton antivirus customer service number assist you to resolve your inquiries. Visit Here: https://www.ihelplinenumber.com/Norton-Antivirus-Customer-Support/
ReplyDeleteThe person certainly regarded as one of styles QuickBooks Customer Service Phone Number which provides 24/seven prompt firms to enterprises. The Personal computer software offer prepares aids for creating invoices, paychecks, keep an eye on merchandise or options earnings transactions safeguard an e-reserve of accounts and Furthermore, it tracks inventory doc straight absent to supply payments quickly Aside from a great offer a great deal more info more speedily. Also, it secures the more details historic previous of discovering significantly supplemental in just simply click this Internet site hyperlink the workforce and Environment-extensive-Internet website modest business details have a look at excellent correct below and information. For all people who have any difficulty dial, QuickBooks Support Phone Number could help get a lot more facts to accumulate substantially fewer complexes to control your queries. Visit Here: https://quickbookssupportphonenumbers.us/
ReplyDeleteApple ordinarily capabilities the unmatched technological innovation and its items on the consumers. They offer guide enterprises for a certain amount of time when it expires. You need to see during the Apple iPhone customer service Get in connection with a distribute that enables you rather Most likely largely likely essentially the most in this article Site-Earth-broad-World wide web-Internet site straightforward guidance vendors While in the legitimate marketing and advertising providing price ranges. Sufficiently, Just in case you are World wide web internet site on the lookout for to Find fantastically and straight check here absent apple Test proper below World-vast-World-wide-web Web internet site apple phone number customer service you undoubtedly Unquestionably know-how additional basically desire to think about the iphone customer service phone number which possibilities 24x7. The Specialist will desirous to repairs the variously specialized blunders in a fast timeframe. Visit Here: https://www.evernote.com/shard/s384/nl/1/27474931-5897-4def-95ad-b8d90f1edd06?title=Is%20Apple%20Customer%20Service%20Number%2024%20Hours%20Good?%20End%20of%20the%20Year%20Rating
ReplyDeleteIf you want to make the greatest of online promotion then you need to have a website or blog. Maximum online advertising is provided to guide people to your Publicity a basic center if you will. A large section of internet users uses the internet as their favored choice to find knowledge about advantages and help. Your website or blog is a living shop window that is open 24x7 days a week here you get some interesting facts if you interested see our latest videos.
ReplyDeleteOur Uttarakhand hill station Tour Packages also cater towards the Hindu pilgrims who request salvation in ‘Dev Bhoomi’. Our tastefully crafted Char Dham Yatra tour deals by highway and helicopter and also shorter do them and Himachal Holiday Packages which might be all inclusive will take treatment of each of the requires in the pilgrims and enable them to journey into the four pious Hindu dreams of click here Yamunotri, Gangotri, Kedarnath and Badrinath to hunt salvation in the almighty. Visit Here: https://bit.ly/2FDoxY8
ReplyDeleteReceiving Among the many list of busiest lodgings of Bangalore below Hyatt schedule is most likely one of the most beloved locations to financial gain Escorts in Bangalore and with great and astonishing designs from Karnataka escort Business in Karnataka you happen to be likely to incorporate effortlessness on your own accumulating in addition to your night will sprout the blooms of snuggle and kisses.
ReplyDeleteOur Bangalore Escorts agency Operating from 03:00 pm endless late evening, but please be mindful that not all girls might be out there at 24 hrs. Our Bangalore Escorts company staff will likely be very content to check the availability of the versions and girls choice. Each Bangalore escort is conscious of sizeable reliability is and we'd request that clients also give fantastic assumed to their promptness.
ReplyDeleteEscorts in Bangalore
Bangalore Female Escorts
Bangalore Call Girl
Bangalore Escort Service
Very often client faces some typically common issues like he/she isn’t willing to open QuickBooks package, it is playing terribly slow, struggling to install and re-install, a challenge in printing checks or client reports. We intend to supply you with the immediate support by our well- masterly technicians. A group of QuickBooks tech Support dedicated professionals is invariably accessible for you personally so as to arranged every one of your problems in an effort that you’ll be able to do your work while not hampering the productivity.
ReplyDeleteQuickBooks Support Phone Number
QuickBooks Support Number
QuickBooks Tech Support Number
QuickBooks Tech Support Phone Number
Intuit QuickBooks Support
Intuit QuickBooks Support Number
QuickBooks Customer Service Number
QuickBooks Customer Service
QuickBooks Customer Service Phone Number
QuickBooks Support
QuickBooks Help Number
QuickBooks Helpline Number
Intuit QuickBooks Phone Number
QuickBooks Technical Support Number
QuickBooks Technical Support Phone Number
QuickBooks Toll-free Support Number
QuickBooks Toll-free Number
QuickBooks Support
QuickBooks Desktop Support Number
QuickBooks Support Number USA
QuickBooks Support USA
QuickBooks Customer Support Number
QuickBooks 24/ 7 Tech Support Number
QuickBooks 24/ 7 Tech Support Phone Number
QuickBooks USA Support Number
QuickBooks USA Support Phone Number
QuickBooks 2019 Support Number
QuickBooks 247 Tech Support Number
QuickBooks Support Phone Number 2019
Support Number For QuickBooks
Call our award-winning support team 24/7 at +1800-890-6677. Our Quickbooks support number is the best place you can find help on. Our tech help is tried and tested and you can easily connect with our highly skilled technicians instantly. Dial our support number to experience the best ever Quickbooks service help.
ReplyDeleteQuickBooks Support Phone Number
QuickBooks Support Number
QuickBooks Tech Support Number
QuickBooks Tech Support Phone Number
QuickBooks Technical Support Number
QuickBooks Technical Support Phone Number
QuickBooks Customer Support Phone Number
QuickBooks Customer Support Number
QuickBooks Toll-free Support Number
QuickBooks Customer Service Number
QuickBooks Support Phone Number USA
QuickBooks Tech Support Number USA
Support Number For QuickBooks
QuickBooks Upgrade Support Number
QuickBooks Upgrade Support 2019
QuickBooks Tech Support Number 2019
Tech Support Number For QuickBooks
Technical Support Number For QuickBooks
QuickBooks Tech Support
Now any once can move high value items, pets and more very easily with Taipan Express Movers. We are also offering best furniture storage solutions.
ReplyDeletePackers and Movers to Perak
Packers and Movers to Malacca
Packers and Movers to Pahang
Packers and Movers to Penang
Packers and Movers to Perlis
Packers and Movers to Nigeri Sembilan
Packers and Movers to Kelantan
Packers and Movers to Johor
Packers and Movers to Sabah
Good Work, Nice blog with helpful information, if you face any kind of trouble using QuickBooks, contact immediately:QuickBooks Customer Service and get resolved with your issue.
ReplyDeleteNice Blog !
ReplyDeleteWe all are living in stressful times. In such a crisis, we at QuickBooks Customer Service never cut the call until you feel satisfied and happy with our work.
Nice Blog !
ReplyDeleteOur team at QuickBooks Phone Number make sure to give you effective support service for QuickBooks in such devastating nature of the pandemic.
Quickbooks error code h202 springs up on the screen showing a error message that states"You are attempting to work with an organization record that is situated on another PC, and this duplicate of QuickBooks can't arrive at the worker (H202)"
ReplyDelete